Wstęp
Kupiłem „Designing Data-Intensive Applications” autorstwa Martina Kleppmann’a, ponieważ szukałem pozycji na temat przetwarzania dużej ilości danych. Zainteresował mnie tutaj przede wszystkim temat przetwarzania strumieniowego i problemy systemów o rozproszonej architekturze. Książka miała bardzo dobre recenzje, więc długo się nie zastanawiałem. Jednak to, co otrzymałem, przeszło moje najśmielsze oczekiwania.
Co w środku?
Jest tu praktycznie wszystko, co trzeba wiedzieć, aby podejmować świadome decyzje. Dowiesz się, jakie są rzeczywiste różnice między poszczególnymi bazami danych (relacyjnymi, dokumentowymi, grafowymi). Poznasz różne sposoby fizycznego przechowywania i organizacji danych w nich (drzewa, indeksy, column storage). Dzięki czemu będziesz wiedzieć, która baza najlepiej się sprawdzi w przypadku Twojego systemu. Znajdziesz tutaj obszerny opis mechanizmów transakcji (poziomy izolacji, serializacja transakcji), partycjonowania danych, replikacji oraz algorytmów wyboru lidera klastra. Jednak tematy te nie są stricte nastawione na bazy danych, ale na wszelkie systemy używające takich mechanizmów (np. Zookeeper).
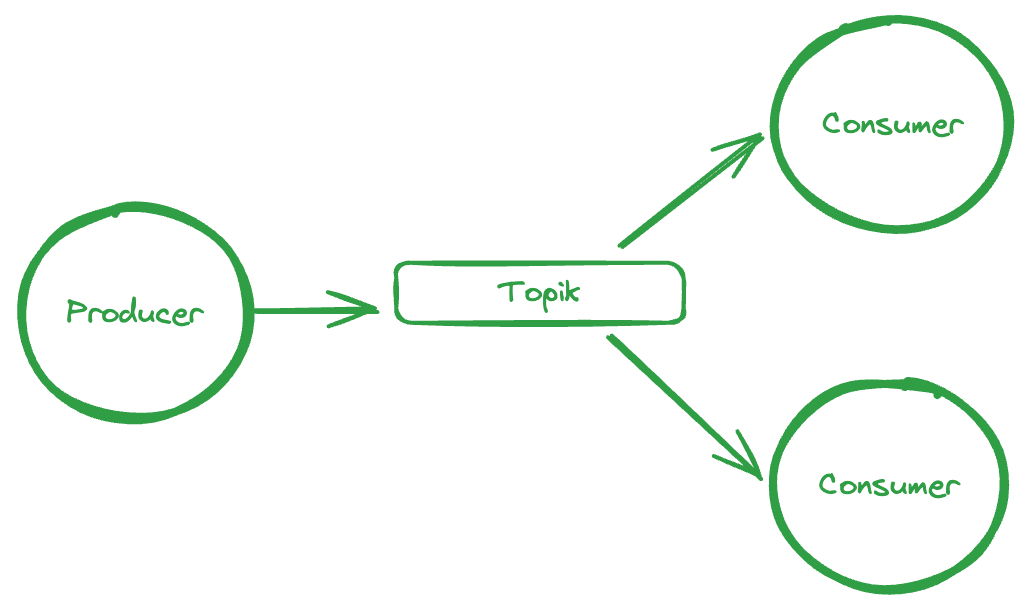
Kolejny duży temat to komunikacja i protokoły kodowania danych (JSON, XML, AVRO, ProtoBuf) wraz z dogłębną analizą ich zalet i wad. Dowiesz się, dlaczego warto używać AVRO i ProtoBuf w systemach opartych na komunikatach. W których komunikat może trochę poczekać na brokerze, zanim zostanie odebrany przez klienta (spoiler: wersjonowanie i wsteczna kompatybilność!).
Dalej przechodzimy do tematów dotyczących głównie systemów rozproszonych. Dowiesz się, z jakimi problemami mierzą się takie systemy (różnice czasu, problemy z siecią, źródło prawdy). Jakie pojawiają się problemy z utrzymaniem spójności (linearność, globalne zapewnienie kolejności operacji, mechanizmy consensusu).
Na koniec, autor opisuje sposoby przetwarzania dużych ilości danych. Zaczynając od najprostszego i jak się okazuje, jednego z najlepszych systemów procesowania strumieniowego — czyli mechanizmu UNIX-owych pipe-ów. Następnie serwuje solidną dawkę wiedzy o wszelkich aspektach algorytmu MapReduce (w tym opis HDFS i join-ów). Po czym przybliża tematykę przetwarzania strumieniowego oraz rozwiązań takich jak CDC (Change Data Capture) czy Event Sourcing.
Dodatkową zaletą, jest to, że każdy rozdział ma potężną bibliografię z minimum 50 pozycjami, a niektóre dochodzą do ponad 100. Także, jeżeli jakiś temat Cię bardziej zainteresuje, masz wytyczoną ścieżkę do poszerzenia wiedzy.
Pełny spis treści możesz zobaczyć na stronie O’Reilly: https://www.oreilly.com/library/view/designing-data-intensive-applications/9781491903063/
Dla kogo?
Zdecydowanie tę pozycję poleciłbym osobom, które podejmują decyzje dotyczące wyboru technologii, architektury. Osobom, które projektują rozwiązania pod konkretne wymagania. O ile ta książka będzie super ciekawą pozycją dla każdego, kogo interesuje tworzenie oprogramowania, to zdecydowanie odradzałbym juniorom, którzy są dopiero na początku swojej drogi. W tym przypadku im więcej mamy wiedzy i doświadczenia przed lekturą, tym więcej z niej wyniesiemy.
Czy warto?
Moim zdaniem zdecydowanie warto. Za około 200 zł, otrzymujesz ponad 500 stron po brzegi wypchanych specjalistyczną wiedzą. Ciężko znaleźć inne, jedno źródło, tak obszernej wiedzy na ten temat. Na dodatek, książka jest bardzo przystępnie napisana, z jasnymi przykładami — po prostu dobrze się ją czyta.
Także podsumowując, nie żałuje ani jednej złotówki wydanej na tę książkę i zdecydowanie polecam.